
🔍 Overview
Okay, 90% of your engineers use my software (Homebrew), but I can't invert a binary tree, so fuck off. Don't worry, after this course, you can. Well, not exactly.
This course goes over the theory and analysis of algorithms. The topics and material heavily follow the textbook, Algorithms. There is not so much a focus on actual coding, but we do sometimes use pseudocode and implement with python. Rather, it trains you to use the fundamental algorithms we've used, and combine and alter their methods to apply them to different problems.
*I took this course Fall 2020, contents may have changed since then
🏢 Structure
- Eight Assignments - 15% (of the final grade)
- Three Coding Quizzes - 10%
- Three Exams - 75%
Assignments
These involve written descriptions, and sometimes pseudocode, on how to solve a given problem. Analyzing its performance and verifying the correctness is also required.
- Dynamic Programming - Notation and methods to solve dynamic programming problems
- DP (Continued) - More problems in the domain
- Divide & Conquer - D&C problem solving and time complexity analysis
- D & C (Continued) - More problems in the domain
- Graph Algorithms - Search algorithms, sorting, and strongly connected components
- Graphs (Continued)- Max flow and more problems in the domain
- NP-Completeness - Problem class distinctions, proofs, and reductions
- Linear Programming - Applications, duality, and algorithms
Coding Quizzes
These are pretty standard problems that require you to implement methods which are then tested against hidden test cases. I won't touch more on these, as they more more-so short exercises than in depth projects.
- Knapsack - Use dynamic programming to solve the knapsack problem
- Find X - Find target x in an infinite array using binary search
- Kruskal's - Implement Kruskal's algorithm and Union Find to find the minimum spanning tree of a graph
Exams
Exams were standard- closed note to be completed in a short time period. The content and problems were similar to that of homework assignments, covering 3-4 weeks of material. In addition, there were multiple choice and short answer problems that touched further topics than the assignments, including but not limited to: cryptography, Euler's method and modular arithmetic
📖 Assignments 1 + 2 - Dynamic Programming
Dynamic Programming (DP) is an algorithmic technique for solving an optimization problem by breaking it down into simpler subproblems and utilizing the fact that the optimal solution to the overall problem depends upon the optimal solution to its subproblems.
The Fibonacci sequence is a problem that captures this well. For any input n, the solution is derived from solutions of subproblems.

A vanilla recursive implementation would have every node in the above tree to be called, which is redundant. A common optimization is to use memoization with recursion (any DP problem can also be solved this way). Recursion is considered a top-down approach, as you start from the highest level and keep going down depths until you reach a base case. DP, on the other hand, is bottom-up, where we start from the base case.
def fib(n):
if n == 0: return 0
dp = [0] * n
# Base cases
dp[0] = 0
dp[1] = 1
for i in range(2, n):
dp[i] = dp[i-1] + dp[i-2]
return dp[i]Dynamic programming solutions have three main components:
- Define your subproblem. For Fib, this is equal to the solution at
- Define your recurrence. How can a solution at be expressed in terms of smaller subproblems? For Fib, this is as simple as its definition
- What are your base cases? We need somewhere to start. For Fib, this is [0, 1].
Results
I thought it would be fun to approach this section of my course reviews differently. Since the results of the homework assignments are typically dense written explanations, I'll instead work through a similar problem under the topic from Leetcode. The problems I pick are similar (some harder some easier) to what we'd see in a homework or exam, but keep in mind we wouldn't have to code them up.
The DP problem is Minimum Number of Removals To Make a Mountain Array. A mountain array has a strictly increasing sequence followed by a strictly decreasing sequence of numbers. For this problem, we need to remove the fewest numbers in an array to make it a valid mountain array.

Here is one of the sample test cases
[2,1,1,5,6,2,3,1]
Output: 3
Explanation: One solution is to remove the elements at indices 0, 1, and 5, making the array nums = [1,5,6,3,1].This can be broken down into the common dynamic programming problem, longest increasing subsequence. We can remove elements in any order, so the problem is essentially finding an increasing subsequence followed by a decreasing subsequence. Removing the elements in between those yields a valid mountain array.
For a dynamic programming solution of LIS,
- Subproblem: = longest increasing subsequence that includes index
- Recurrence: where
- Base case: initialize with all ones

To find the longest decreasing subsequence (LDS), we just need to sweep from right to left instead. Alternatively, we could change the comparator from less than to greater than in the recurrence relation. Running both on the example above gives arrays:
Input arr: [2, 1, 1, 5, 6, 2, 3, 1]
LIS: [1, 1, 1, 2, 3, 2, 3, 1]
LDS: [2, 1, 1, 3, 3, 2, 2, 1]Now, to find the largest mountain, we just need to look for the shared point between the increasing subsequence and decreasing subsequence that yields the longest combination. This is the highest sum of the same index between both arrays- in this case, it is at index 5, where the sum is 3 and 3. Since they share the same center, we need to subtract 1, and the longest mountain is size 5! Subtracting this from the total length of the array gives the minimum number of removals.
def minimumMountainRemovals(self, nums: List[int]) -> int:
# t is the LIS, t_rev is the LDS
t = [1] * len(nums)
t_rev = [1] * len(nums)
for i in range(1, len(nums)):
for j in range(0, i):
# Update our table based on the recurrence relation
if nums[i] > nums[j]:
t[i] = max(t[i], t[j] + 1)
for i in range(len(nums) - 2, -1, -1):
for j in range(len(nums) - 1, i, -1):
if nums[i] > nums[j]:
t_rev[i] = max(t_rev[i], t_rev[j] + 1)
best = 0
for i in range(0, len(t)):
# Now, find the best shared point.
# We need to check that both are > 1
# If not, then the sequence would only be 1 direction
if t[i] > 1 and t_rev[i] > 1:
best = max(best, t[i] + t_rev[i])
return len(nums) - best + 1This solution runs in , since for the LIS, we pass through all previous elements for each index. There is an solution that is possible.
📖 Assignments 3 + 4 - Divide and Conquer
The divide-and-conquer strategy solves a problem by:
- Breaking it into subproblems that are themselves smaller instances of the same type of problem
- Recursively solving these subproblems
- Appropriately combining their answers
The most common and probably well-known algorithm that uses this is probably merge sort. This sorting algorithm breaks down an unsorted array into two halves and then merges the two sorted halves.

The runtime complexity of this is O(nlog(n)). This is because for every level of merging, we pass through every element exactly 1 time, and there are log(n) levels, so the total number of operations is proportional to multiplying those two together.
The master-theorem expresses a runtime complexity for varying D&C problems.

Results
The D&C problem is Merge K-Sorted Lists. We are given a list of K sorted linked lists, and we want to merge all of them into one sorted linked list.
This can be solved by straightforward divide & conquer similar to merge sort. You break down all linked lists until they are of size 1. Combining two sorted linked lists is the same general technique as two sorted arrays. Each level forward, two combined linked lists will yield one sorted linked list, until it is all combined and returned!
def mergeKLists(self, lists: List[ListNode]) -> ListNode:
if not lists:
return None
# Keep splitting until there's at most 1 element
if len(lists) == 1:
return lists[0]
mid = len(lists) // 2
l, r = self.mergeKLists(lists[:mid]), \
self.mergeKLists(lists[mid:])
# This return will first be reached at the lowest level
return self.merge(l, r)
def merge(self, n1, n2):
'''
Alternatively, a recursive in-place solution could be used
'''
root = curr = ListNode()
# Combine the two sorted lists
while n1 and n2:
curr.next = ListNode()
curr = curr.next
if n1.val < n2.val:
curr.val = n1.val
n1 = n1.next
else:
curr.val = n2.val
n2 = n2.next
# At this point, we need at most 1 more pointer to handle
# the rest of the sorted values
curr.next = n1 or n2
return root.next📖 Assignments 5 + 6 - Graph Algorithms
Content
A wide range of problems in different domains can be represented concisely in graphs. A graph is defined by a set of vertices and edges which may or may not specify direction and weight.


The majority of operations within graphs that we encountered were:
- Search (DFS/BFS, Dijkstra's, MST, Strongly Connected Components)
- Flow-based (Edmund Karp, Max-flow mincut, ford fulkerson)
- Ordering (Topological sort)
- Manipulations (Removing, reversing, and adding edges)
We would typically use these algorithms as a black box with some modifications to solve for the problem at hand.
Results
Here's a problem that does not seem immediately seem like a graph problem, Alien Dictionary.
There is an "alien" language that uses the english alphabet, but the ordering between letters is unknown (ex. instead of abcdef... it might be bpaoef...). Given a list of words which are sorted lexicographically, return the order of the letters in this language. An example:
Input: words = ["wrt","wrf","er","ett","rftt"]
Output: "wertf"
# 'w' must be first, followed by 'e' and 'r' since they are the 1st chars
# We know 't' is before 'f', since it is the only char that distiguishes
# words 'wrt' and 'wrf'We know which character comes first one at a time, so we can map this relation for every single character to construct a directed graph. This can be constructed by comparing each word at with that at , and finding the first changed character. For ['wrf', 'er'], this is 'w' and 'e'. For ['wrt', 'wrf'], this is 't' and 'f'. The direction of the edge is second → first, so 'e' → 'w', and 'f' → 't'
Topological sorting for directed acyclic graph is a linear ordering of vertices such that for every directed edge (u, v), vertex u comes before v in the ordering. In this case, we want the direct opposite, so the furthest down is returned first. The direction is somewhat arbitrary, since you can return a reversed order, or point the edges in a reversed direction to achieve the same result.
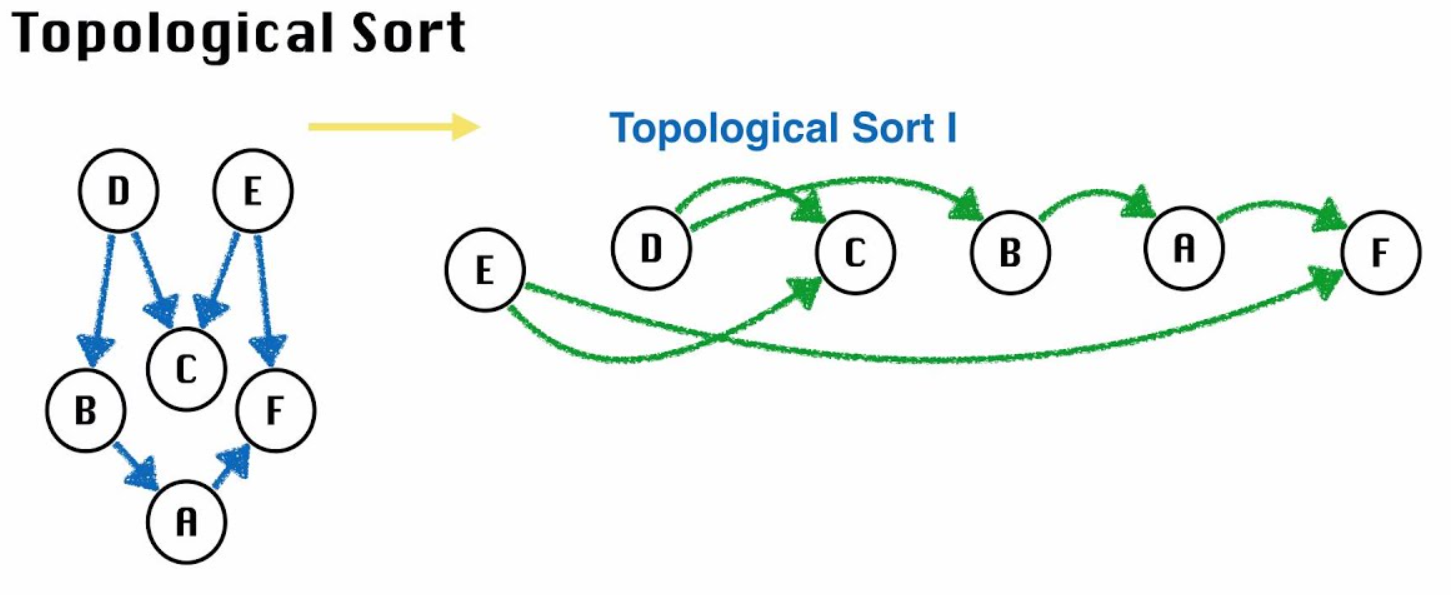
There are a few methods to find the sorting, but to me the simplest is to use depth-first search, and I used that for my solution to alien dictionary. For each vertex, in any order, you run DFS on its outgoing edges, and after it returns for the current node, add the vertex to the solution.
If you first call the vertex at the highest level, then only after it traverses through the depths will it be added. Alternatively, if you first call a vertex with no outgoing edges, it is immediately added to the output. Both will yield the same solution, though vertices with the same degrees may not return in the same order. With this approach we get to ignore in-degree and out-degrees!
def alienOrder(self, words: List[str]) -> str:
graph = {c: set() for word in words for c in word}
# Construct the directed graph
for first, second in zip(words, words[1:]):
for c_first, c_second in zip(first, second):
if c_first != c_second:
graph[c_second].add(c_first)
break
else: # Didn't find anything in the above
if len(second) < len(first): return ""
order = []
visited = set()
for key in graph.keys():
no_cycle = self.dfs(graph, key, visited, order)
# We need to consider invalid inputs. If there is a cycle
# it is invalid. 'not no_cycle' means it has a cycle!
if not no_cycle:
return ''
return ''.join(order)
def dfs(self, graph, c, visited, order):
'''
Searches through and returns whether a cycle was found or not
'''
if c in visited:
if c not in order:
# If we're here, a node was visited a second time
# before it's added to the solution, so it's a cycle
return False
return True
visited.add(c)
for c_next in list(graph[c]):
no_cycle = self.dfs(graph, c_next, visited, order)
if not no_cycle:
return False
# Only after the DFS returns, we add to the result
order.append(c)
return True📖 Assignment 7 - NP-Completeness
There are many great resources out there which define and provide examples for complexity classes P, NP, NP-Complete, and NP-Hard, so I'll instead touch on the main topic for the class, which is reductions.

We can prove that a problem is NP-Complete by demonstrating that it is in class NP (can it be verified in polynomial time?), and showing that it is at least as hard as a known NP-Complete problem, by reduction.
A reduction from problem A → problem B can be done by showing that A can be converted to B, converting the solution from B back to A, and showing that a solution to B exists iff a solution to A exists. The conversions must be done in polynomial time. In this case, problem A is the known NP-Complete problem, and B is what we are trying to prove for.
Let's say we want to prove that the problem, clique, is NP-Complete. Given an undirected graph find the a set of vertices of size k where an edge connects every pair together. Application: what is the largest set of friends on Facebook where everybody is friends with each other?

We first prove that this is in class NP by showing a given result is a valid clique. For every vertex, we check that there is an edge connecting to every other vertex, and if any are missing, it is not valid. This runs in time, where is the number of vertices.
Let's consider the known NP-Complete problem, independent set. Given an undirected graph, find a set of vertices of size k where there are no edges which connect any pair. Application: alternatively, what is the largest set of users on Facebook where nobody is friends with each other?
To finish the proof that clique is NP-Complete, we can show a reduction from independent set to clique. I won't prove all steps here, but at the high level, an independent set of graph is the clique of complementary graph . This conversion can be done in time.

The homework problems and exams required some pretty clever conversions that are not as clear as the case above. We were provided a list of NP-Complete problems we could reduce from. There was a large focus on proper proofs that cover all the steps.
Results
We're not exactly going to demonstrate a reduction proof here, but there are some NP-Complete problems on Leetcode. Find the shortest superstring is a problem that can be converted to the Travelling Salesman Problem. Given a list of strings, find the smallest string (the superstring) which contains each string as a substring.
Input: ["catg","ctaagt","gcta","ttca","atgcatc"]
Output: "gctaagttcatgcatc"
# gctaagttcatgcatc
# gcta
# ctaagt
# ttca
# catg
# atgcatcI'll first mention that the reductions we had to do for the course were not nearly as abstract or complicated as this.
So how is this a search problem? In constructing a minimum superstring, we want to maximize the number of overlaps that occur. By brute force, we can solve this in time, so for the example we have, this would be , which is checking every combination of the 5 strings and calculating the overlap.
Instead, we can represent this as a graph. Each input string is a vertex, and the edges are the overlaps from each vertex to the others. Once we calculate the overlap between every single string, we find the path between every string that has the highest value. This is because the highest overall overlap results in the smallest string. Now, this is the TSP, except we want the longest path, and we don't need to return to the original location!
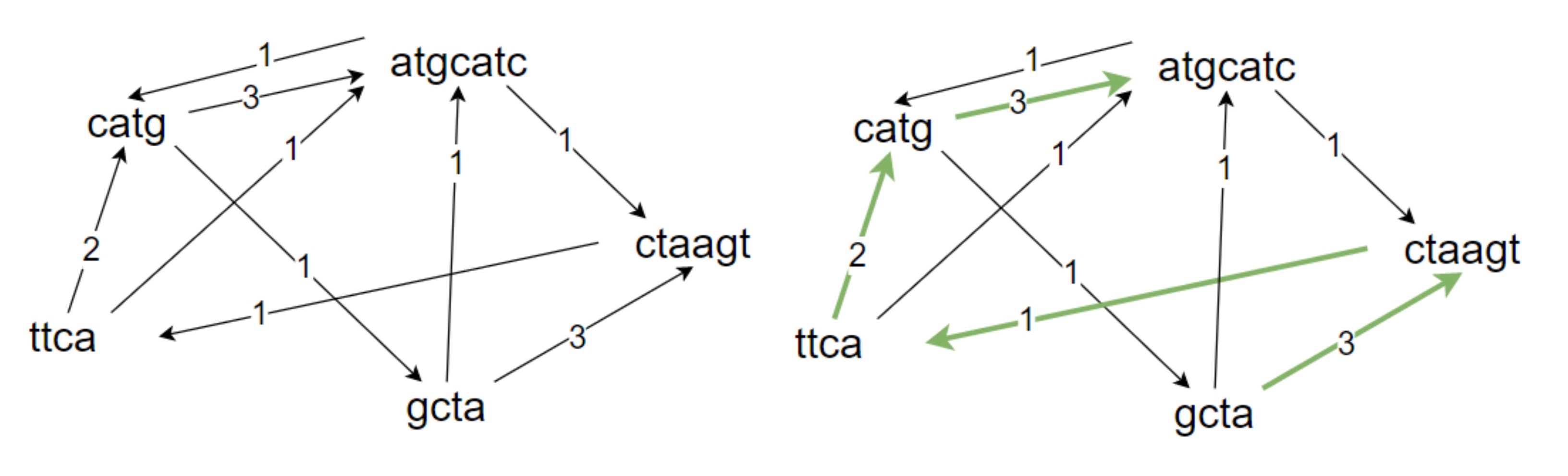
# For input ["catg","ctaagt","gcta","ttca","atgcatc"]
'''
For input ["catg","ctaagt","gcta","ttca","atgcatc"]
This will generate a matrix with the above edge weights
0s are omitted from my graph, but they are still a valid path to take.
'''
n = len(words)
shared = [[0] * n for _ in range(n)]
# Loop over every combination of two words. Order matters, ij != ji
for i in range(n):
for j in range(n):
if i != j: # Ignore when our word is the same
a, b = words[i], words[j]
# Find the longest substring from 'b' that overlaps the back of 'a'
for k in range(min(len(a), len(b)), -1, -1):
if a[-k:] == b[:k]:
shared[i][j] = k
breakThis is as far as I'll go. A dynamic programming solution is the Held-Karp algorithm, which runs in time. This is still not ideal, but it is better than factorial time. I believe most deployed applications of TSP utilize an approximate solution when the graph becomes too large.
📖 Assignment 8 - Linear Programming
Linear programming is an optimization task where you are given an objective function to maximize, as well as a set of constraints, all of which are linear functions. We didn't spend too much on this topic in this course, but the focus was on breaking down problems and converting them to be standard form for linear programming, as well as some theory. Not so much on algorithms to solve on them.
A common problem that can actually be expressed by linear programming is finding the max flow of a graph. We are given a graph where each edge represents a maximum capacity of flow, and the source + destination vertices. What is the maximum flow that can be achieved, given flow never surpasses the capacity of an edge, and the outgoing flow at a vertex is always equal to the incoming flow (except at the source and destination).

Ford-Fulkerson is a well known algorithm to solve this problem optimally. We can formulate it as a linear program.
maximize:
subject to:
for all edges except source & destination
for all edges
for all edges
Here, we want to maximize the sum of the flow. The first constraint means that, for every vertex, the incoming flow is equal to the outgoing flow. The second means that the flow at any edge is less than the or equal to its capacity. Finally, we want to ensure that the flow is non-negative.
We had a mix of higher-level problems to formulate into linear programs, as well as more algorithmic based, and taking existing linear programs and reworking them to fit under a modified problem.
⏩ Next Steps
Graduate Algorithms provides the theoretical and practical structure to begin to think about more complex problems. For further work, there are many directions one could go into. In addition to a breadth of topics, you can look into further mathematical analysis. Also, it would be interesting to find algorithmic optimizations not just for runtime complexity, but considering computer processor characteristics as well.

